Benchmarking the Robustness of LiDAR Semantic Segmentation Models
ArXiv
- Xu Yan CUHK-SZ
- Chaoda Zheng CUHK-SZ
- Zhen Li CUHK-SZ
- Shuguang Cui CUHK-SZ
- Dengxin Dai MPI for Informatics
Abstract
When using LiDAR semantic segmentation models for safety-critical applications such as autonomous driving, it is essential to understand and improve their robustness with respect to a large range of LiDAR corruptions. In this paper, we aim to comprehensively analyze the robustness of LiDAR semantic segmentation models under various corruptions. To rigorously evaluate the robustness and generalizability of current approaches, we propose a new benchmark called SemanticKITTI-C, which features 16 out-of-domain LiDAR corruptions in three groups, namely adverse weather, measurement noise and cross-device discrepancy. Then, we systematically investigate 11 LiDAR semantic segmentation models, especially spanning different input representations (e.g., point clouds, voxels, projected images, and etc.), network architectures and training schemes. Through this study, we obtain two insights: 1) We find out that the input representation plays a crucial role in robustness. Specifically, under specific corruptions, different representations perform variously. 2) Although state-of-the-art methods on LiDAR semantic segmentation achieve promising results on clean data, they are less robust when dealing with noisy data. Finally, based on the above observations, we design a robust LiDAR segmentation model (RLSeg) which greatly boosts the robustness with simple but effective modifications. It is promising that our benchmark, comprehensive analysis, and observations can boost future research in robust LiDAR semantic segmentation for safety-critical applications.
Overview
Examples of our proposed SemanticKITTI-C. We corrupt the clean validation set of SemanticKITTI using six types of corruptions with 16 levels of intensity to build upon a comprehensive robustness benchmark for LiDAR semantic segmentation. Listed examples are point clouds on 16-beam LiDAR sensors, with global and local distortion, in snowfall and fog simulations.
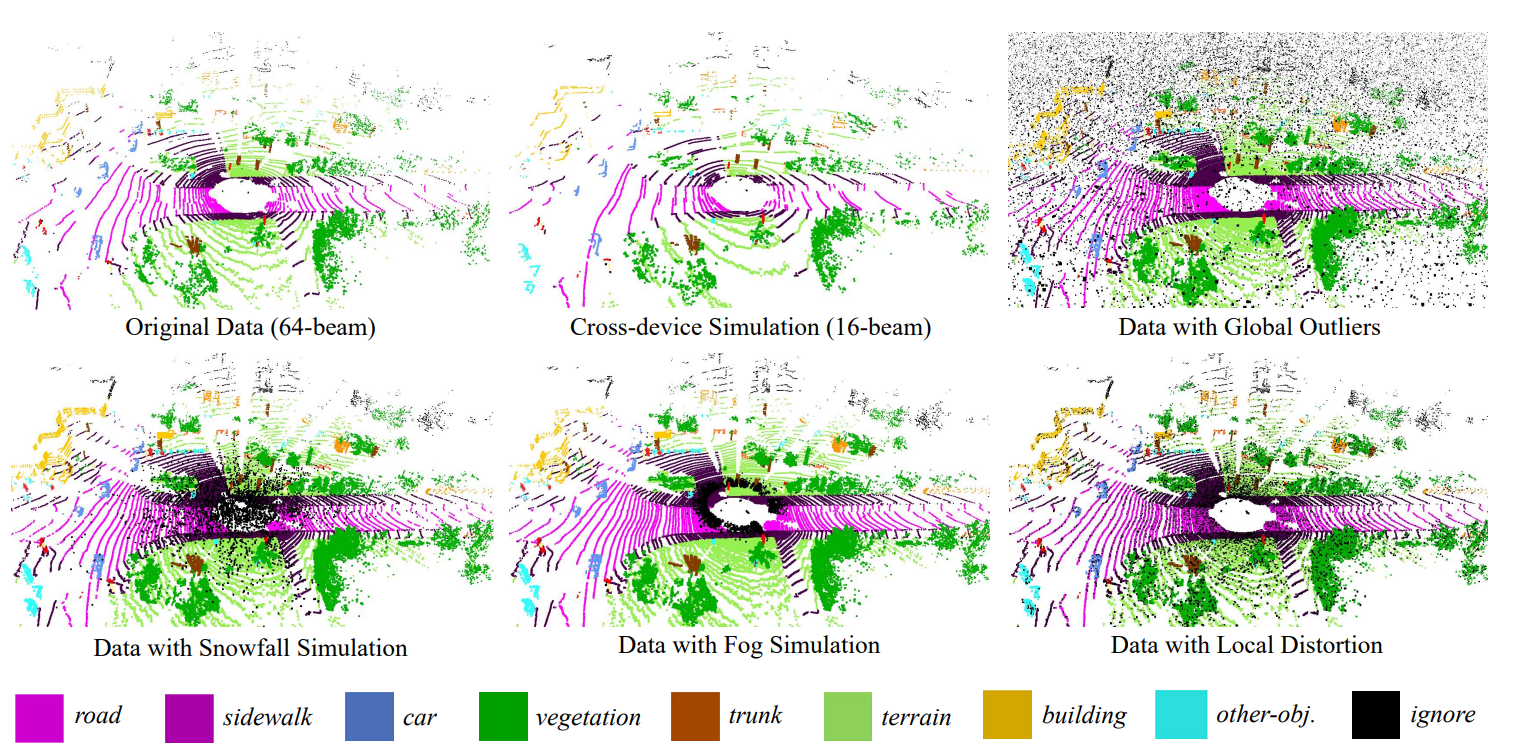
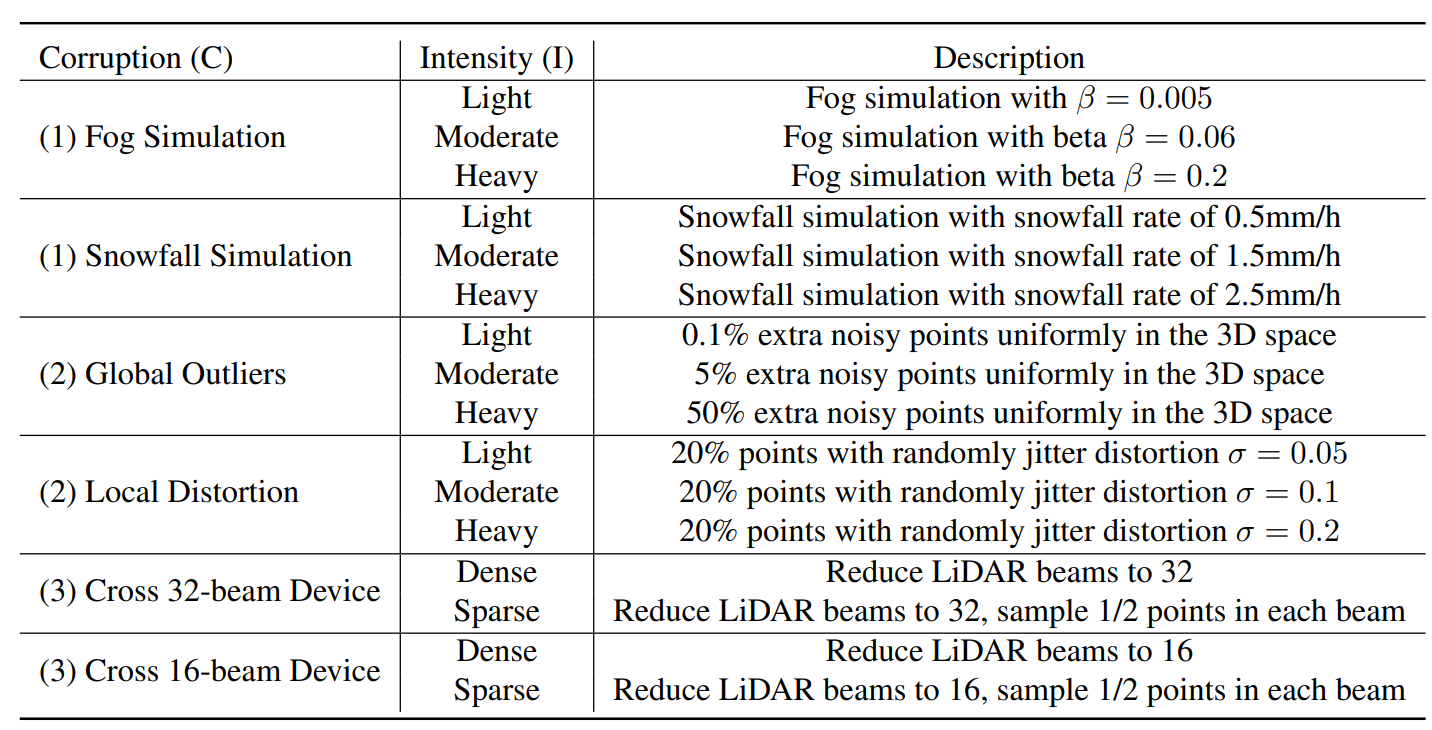
We categorize common LiDAR corruptions into three domains: (1) adverse weather conditions, (2) measurement noise and (3) cross-device discrepancy.
We benchmark 11 existing methods for LiDAR semantic segmentation.
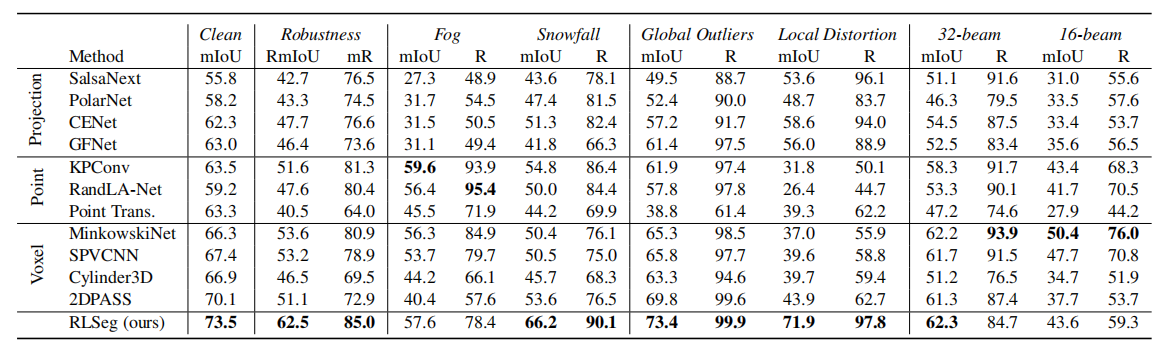
Benchmarking Results
Benchmarking the robustness of state-of-the-art methods in all 16 scenarios (6 classes) on SemanticKITTI-C. R denotes the relative mean robustness performance of the model. The higher R means the model is more robust to inferior LiDAR conditions.
Citation
If you find our work useful in your research, please consider citing:
@article{yan2023benchmarking,
title={Benchmarking the Robustness of LiDAR Semantic Segmentation Models},
author={Yan, Xu and Zheng, Chaoda and Li, Zhen and Cui, Shuguang and Dai, Dengxin},
journal={arXiv preprint arXiv:2301.00970},
year={2023}
}